혼자 만든 Code
bithumb 특정 코인의 오늘 종가,최고가, 최저가 예측 프로그램
빛하루
2024. 12. 1. 01:56
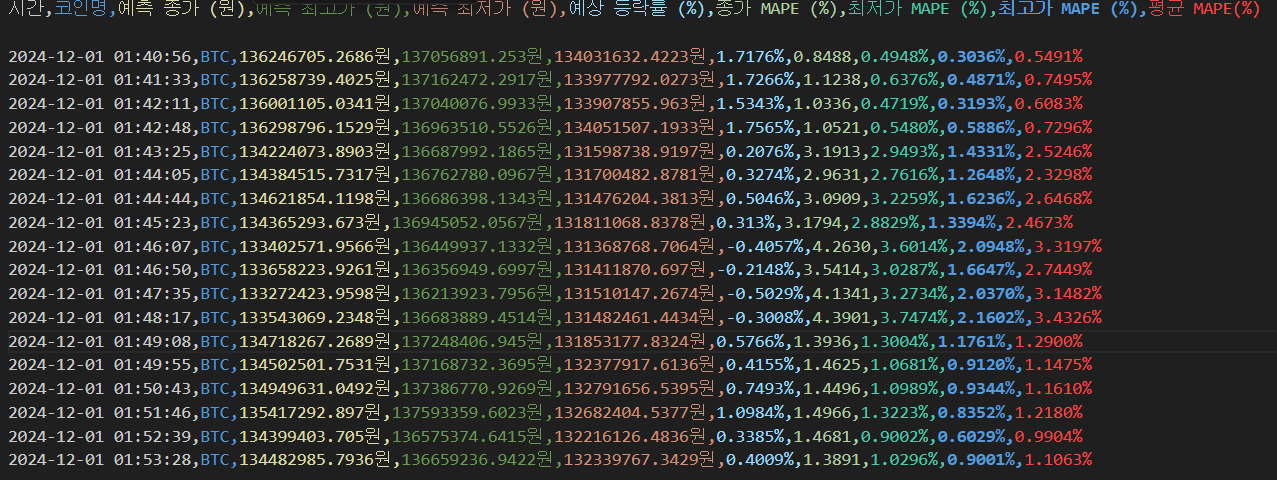
※예측 결과
import requests
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.model_selection import train_test_split
import os
import matplotlib.pyplot as plt
from datetime import datetime
# 1. Bithumb API 특정 코인의 최근 100일 일봉 데이터 가져오기
def fetch_last_100_days(coin_name,min_data, base_currency="KRW", csv_file="coin_daily_data.csv"):
# CSV 파일 초기화
if os.path.exists(csv_file):
os.remove(csv_file) # 파일 삭제
url = f"https://api.bithumb.com/public/candlestick/{coin_name}_{base_currency}/24h"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
if data['status'] == '0000': # 성공 코드
candles = data['data']
df = pd.DataFrame(candles, columns=['timestamp', 'open', 'close', 'high', 'low', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.rename(columns={'timestamp': 'date'}, inplace=True)
df['open'] = df['open'].astype(float)
df['close'] = df['close'].astype(float)
df['high'] = df['high'].astype(float)
df['low'] = df['low'].astype(float)
if len(df) >= 151: # 일봉 데이터가 366개 이상인 경우만 반환
# 이동평균선 추가
df['MA5'] = df['close'].rolling(window=5).mean()
df['MA10'] = df['close'].rolling(window=10).mean()
df['MA20'] = df['close'].rolling(window=20).mean()
# CSV 파일 저장
df = df.iloc[:-1]
df.to_csv(csv_file, index=False)
print(f"{csv_file} 파일에 데이터를 저장했습니다.")
return df[['date', 'open', 'close', 'high', 'low', 'MA5', 'MA10', 'MA20']].tail(min_data)
return None
# 2. 데이터 전처리
def preprocess_data(data, lookback):
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)
X, y = [], []
for i in range(lookback, len(scaled_data) - 1):
X.append(scaled_data[i - lookback:i]) # lookback 기간의 데이터
y.append(scaled_data[i, 0:4]) # 예측할 값 (시가, 종가, 최고가, 최저가)
return np.array(X), np.array(y), scaler
# 3. LSTM 모델 설계
def create_model(input_shape):
model = Sequential([
LSTM(64, activation='relu', return_sequences=True, input_shape=input_shape),
LSTM(32, activation='relu'),
Dense(4) # open, close, high, low 예측
])
model.compile(optimizer='adam', loss='mse')
return model
# 4. 데이터 학습 및 예측
def train_and_predict(data, lookback, test_size):
X, y, scaler = preprocess_data(data[['open', 'close', 'high', 'low', 'MA5', 'MA10', 'MA20']], lookback)
if len(X) == 0: # 학습 가능한 데이터가 부족하면 건너뜀
return None, None
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42, shuffle=False)
model = create_model((X_train.shape[1], X_train.shape[2]))
model.fit(X_train, y_train, epochs=200, batch_size=16, verbose=0)
# 마지막 시퀀스 데이터로 예측
last_sequence = X[-1].reshape(1, X.shape[1], X.shape[2])
predicted = model.predict(last_sequence)
# 예측된 데이터에서 시가, 종가, 최고가, 최저가만 추출
predicted = scaler.inverse_transform(np.hstack((predicted, np.zeros((predicted.shape[0], X.shape[2] - 4)))))
# 실제 값에 MA5, MA10, MA20을 추가하여 원래 차원 맞추기
actual_with_ma = np.hstack((y[-1], np.array([data['MA5'].iloc[-1], data['MA10'].iloc[-1], data['MA20'].iloc[-1]])))
return predicted[0], scaler.inverse_transform([actual_with_ma])[0] # (예측값, 실제값)
# 5. 특정 코인에 대해 20번 학습 후 예측값 평균 계산
def analyze_coin(coin_name, lookback, min_data, iterations=20, test_size=0.5, csv_file="coin_daily_data.csv"):
data = fetch_last_100_days(coin_name, min_data, csv_file=csv_file)
if data is None or len(data) < min_data: # 최소 데이터 조건
print(f"{coin_name} 데이터가 충분하지 않거나 불러오지 못했습니다.")
return
last_close_price = data['close'].iloc[-1]
predictions = []
actuals = []
for i in range(iterations):
print(f"Training iteration {i+1}...")
predicted, last_actual = train_and_predict(data, lookback, test_size)
# 예측된 종가가 범위 내에 있을 때까지 반복
while predicted is not None and (predicted[3] > predicted[1] or predicted[3] > predicted[2] or predicted[1] < predicted[3]):
print(f"Iteration {i+1}: 예측된 종가가 범위 밖입니다. 다시 예측합니다.")
predicted, last_actual = train_and_predict(data, lookback, test_size)
if predicted is not None:
predictions.append(predicted)
actuals.append(last_actual)
if not predictions:
print(f"{coin_name}에 대한 예측값을 얻지 못했습니다.")
return
# 예측값들의 평균 계산
predictions = np.array(predictions)
actuals = np.array(actuals)
mean_predicted = predictions.mean(axis=0)
mean_actual = actuals.mean(axis=0)
mape_close = np.mean(np.abs((predictions[:, 1] - actuals[:, 1]) / actuals[:, 1])) * 100
mape_high = np.mean(np.abs((predictions[:, 2] - actuals[:, 2]) / actuals[:, 2])) * 100
mape_low = np.mean(np.abs((predictions[:, 3] - actuals[:, 3]) / actuals[:, 3])) * 100
mape_total = (mape_close + mape_high + mape_low) / 3
mean_error = last_close_price/mean_predicted[0]
change_ratio = (mean_predicted[1] * mean_error - last_close_price) / last_close_price * 100
print(f"\n{coin_name} - 예측값 평균:")
print(f"예측 종가: {mean_predicted[1] * mean_error:.4f} 원")
print(f"예측 최고가: {mean_predicted[2] * mean_error:.4f} 원")
print(f"예측 최저가: {mean_predicted[3] * mean_error:.4f} 원")
print(f"예상 등락률: {change_ratio:.4f}%")
print(f"평균 종가 절대 백분율 오차 (MAPE): {mape_close:.4f}%")
print(f"평균 최고가 절대 백분율 오차 (MAPE): {mape_high:.4f}%")
print(f"평균 최저가 절대 백분율 오차 (MAPE): {mape_low:.4f}%")
print(f"전체 MAPE (평균): {mape_total:.4f}%")
output_file = f"20241130_{coin_name}_daily_predict_ver1.1.csv"
# 초기 CSV 파일 생성 (헤더 추가, 최초 실행 시)
try:
with open(output_file, 'x', encoding='utf-8-sig') as f:
pd.DataFrame(columns=["시간", "코인명", "예측 종가 (원)", "예측 최고가 (원)", "예측 최저가 (원)", "예상 등락률 (%)","종가 MAPE (%)","최저가 MAPE (%)","최고가 MAPE (%)","평균 MAPE(%)"]).to_csv(f, index=False)
except FileExistsError:
pass # 파일이 이미 존재하면 헤더를 추가하지 않음
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
new_data = pd.DataFrame({
"시간": [current_time],
"코인명": [coin_name],
"예측 종가 (원)": [f'{np.round(mean_predicted[1] *mean_error, 4)}원'],
"예측 최고가 (원)": [f'{np.round(mean_predicted[2] * mean_error, 4)}원'],
"예측 최저가 (원)": [f'{np.round(mean_predicted[3] * mean_error, 4)}원'],
"예상 등락률 (%)": [f'{np.round(change_ratio, 4)}%'],
"종가 MAPE": [f'{mape_close:.4f}'],
"최저가 MAPE": [f'{mape_low:.4f}%'],
"최고가 MAPE": [f'{mape_high:.4f}%'],
"평균 MAPE": [f'{mape_total:.4f}%']
})
# CSV 파일이 없으면 헤더 포함, 있으면 데이터 추가
if not os.path.exists(output_file):
new_data.to_csv(output_file, index=False, encoding='utf-8-sig')
else:
new_data.to_csv(output_file, index=False, mode='a', header=False, encoding='utf-8-sig')
coin_name = input('분석할 코인의 종목 : ')
for i in range(10, 51, 10):
for j in range(1,5):
analyze_coin(coin_name, lookback=2, iterations=10, test_size=0.1, min_data=i)